双卡实现20FPS实时数字人推理,Soul张璐团队破解数字人实时算力瓶颈
随着AI技术在数字人直播、视频播客等场景的快速普及,行业需求正从单纯的“能生成”向“能长期稳定生成”进阶。然而,现有技术在拉长视频时长后,普遍面临画面稳定性与一致性下降的难题。为此,Soul张璐团队发布了开源模型 SoulX-LiveAct。该模型在2张H100/H200条件下即可实现20 FPS实时流式推理,并支持多模态驱动以生成高质量实时数字人视频,为行业提供了极具价值的差异化技术方案。
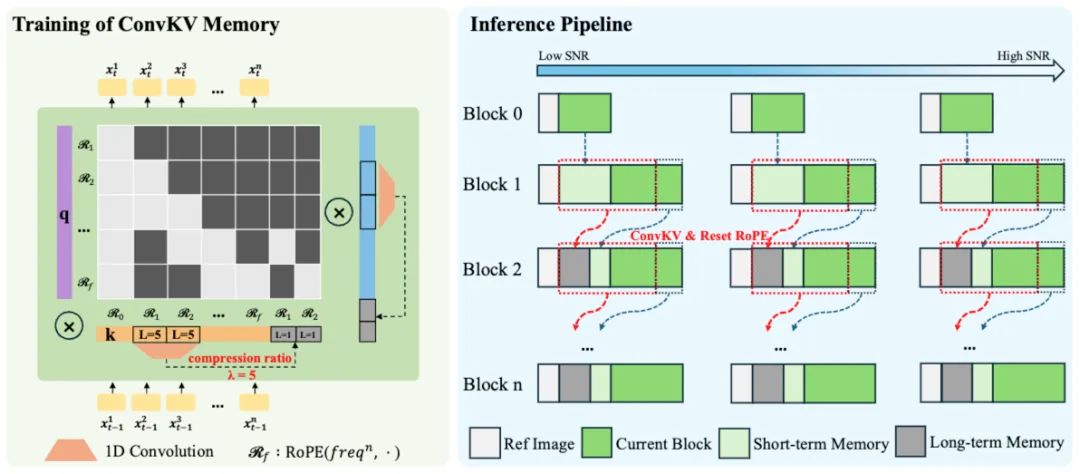
三大核心技术突破,夯实模型差异化优势
SoulX-LiveAct针对行业现存痛点,从显存机制、实时算力、长时细节三个方向实现关键创新,构成自身核心竞争力。在显存管控层面,传统AR diffusion模型依赖KV cache记录历史信息,缓存随时长线性增加,易引发显存溢出或历史信息丢失,直接破坏画面稳定性。SoulX-LiveAct从“条件传播方式”和“历史记忆管理”两个层面解决了这一瓶颈,创新机制使系统既能“带得动”长时历史,又不会因缓存膨胀而拖慢推理,从而在机制上具备小时级甚至更长时长的持续生成能力。
实时性与算力成本是数字人规模化应用的关键门槛。在512×512分辨率下,SoulX-LiveAct仅需2张H100/H200即可达到20 FPS的实时流式推理能力,端到端延迟约 0.94s。同时,单帧计算成本降低到27.2 TFLOPs / frame,在追求实时的条件下显著减轻算力压力,为线上部署提供更现实的成本方案。针对长视频数字人普遍存在面部偏移、服饰饰品消失、口型逐渐错位等问题,SoulX-LiveAct可在长时间生成过程中稳定维持人物身份,保障发型、衣纹、配饰等关键细节完整呈现,实现全程画面连贯统一。
综合性能全面领先,适配多场景落地需求
研究团队基于HDTF面部口型数据集、EMTD全身动作数据集开展定量评测,全面验证模型综合能力。在HDTF上,SoulX-LiveAct取得9.40的Sync-C与6.76的Sync-D,同时在分布相似性指标上达到10.05 FID / 69.43 FVD,并在VBench上获得97.6的 Temporal Quality与63.0的 Image Quality,VBench-2.0的 Human Fidelity达到99.9,体现出更稳定的时序质量与更强的人体与身份一致性;在EMTD全身动作场景下,依旧保持高同步性,各项质量指标稳居前列,可适配复杂动作与表情交互。依托优异性能,该模型可应用于长期在线数字人直播、AI教学、智慧服务、虚拟NPC互动等场景,满足长时间、高真实感的虚拟角色交互需求。

Soul张璐团队立足行业实际应用痛点,以底层技术创新破解长时数字人稳定性难题,凭借可落地的算力方案与扎实的实测数据,不仅完成了自身AI基础设施的持续升级,更为开源生态与数字人商业化应用提供了可靠的技术参考与实践范本。
相关文章:
相关推荐: